Amazon Kinesisについて勉強
AWS 認定ソリューションアーキテクト ? アソシエイトを受けるため、改めてAmazon Web Service(AWS)の勉強をする。
今回もこの本を一読したうえで機能単位で勉強していく。

- Kinesis Data Streams
- Amazon Kinesis Firehose
- Amazon Kinesis Analytics
- Kinesis系機能3種類の組み合わせでストリーム処理を実施する
Kinesis Data Streams
Iotやゲームなどのストリームデータを処理するアプリケーションを構築する機能。
基本的な特徴は以下の3点
- 管理が容易:必要なキャパシティをセットしてストリームを作成するだけ。スループットやデータ量の変化に応じてスケール
- 独自のリアルタイムアプリケーション:Amazon Kinesis Client Library, Apache Spartk/Flink, AWS Lambdaを利用してストリーム処理を実装
- 低コスト
主要なコンセプト

https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
inputのIotデータなど、データ送信側が数百万のソースが1時間に何百TBのデータを生成しても処理することが可能。
それぞれのデータの単位をデータレコードといい、Amazon Kinesis Streams内でデータを保持することもできる。
ただし、保持できる期間はデフォルトで24時間、最長7日間であるため、保持し続けて翌週に取得等の場合データがなくなっている場合があるので注意。
Amazon Kinesis Streams内でデータは3AZで複製するされるため強い整合性を持つ。
データ種類別でストリームを設定、それぞれデータ単位で1つ以上のシャードで構成される(水平構成をすることで高速化を実現)。
各シャードの振り分けは、データ入力時のパーティションキーで決定するため、パーティションキーをうまく設定しないと、シャードへのデータの流入が偏って速度が出ないということもあり得る。
データレコードの順序性
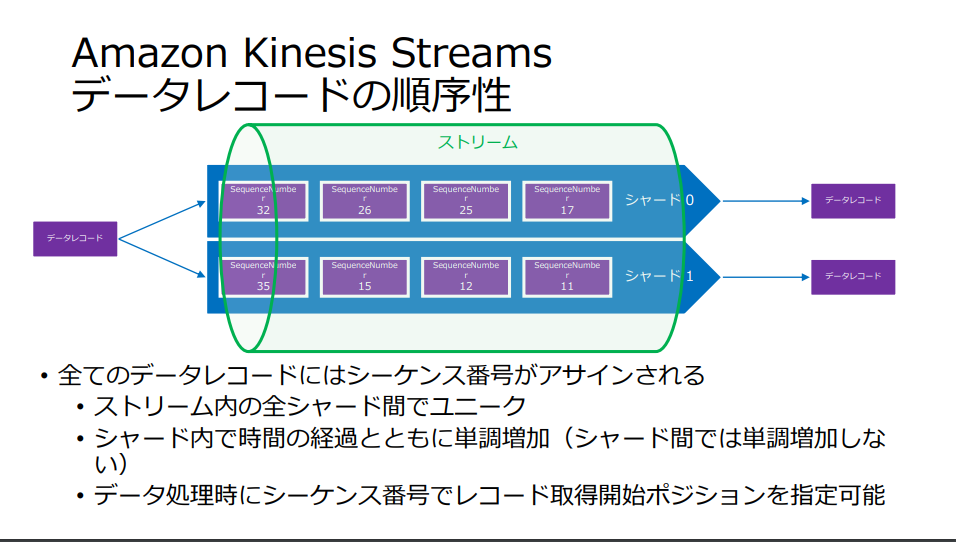
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
複数のシャードの中では、それぞれのデータソースが存在するが、データレコードにはユニークなシーケンス番号がセットされており、シーケンス番号順で処理される。
Amazon Kinesis Streamsへの送信、処理する機能
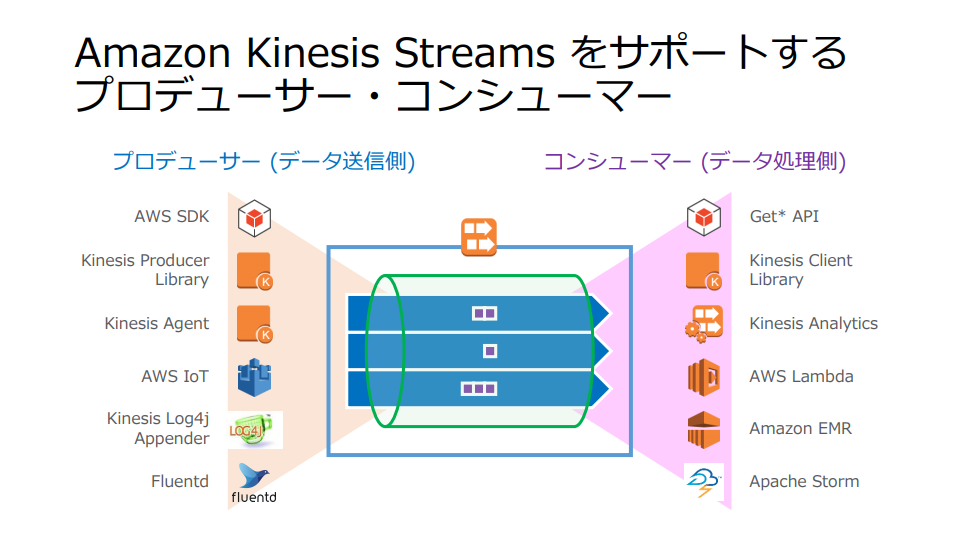
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用

Amazon Kinesis Data Streams(リアルタイム分析向け大規模データを収集)| AWS より引用
Kinesis StreamsとEMRとの連携
そのため順序付きのイベントストリームとして複数のアプリケーションから同時アクセスが可能EMRと統合し分散データを処理することで、より大量のデータを処理できる点やレイテンシーを上げずに処理することが可能。
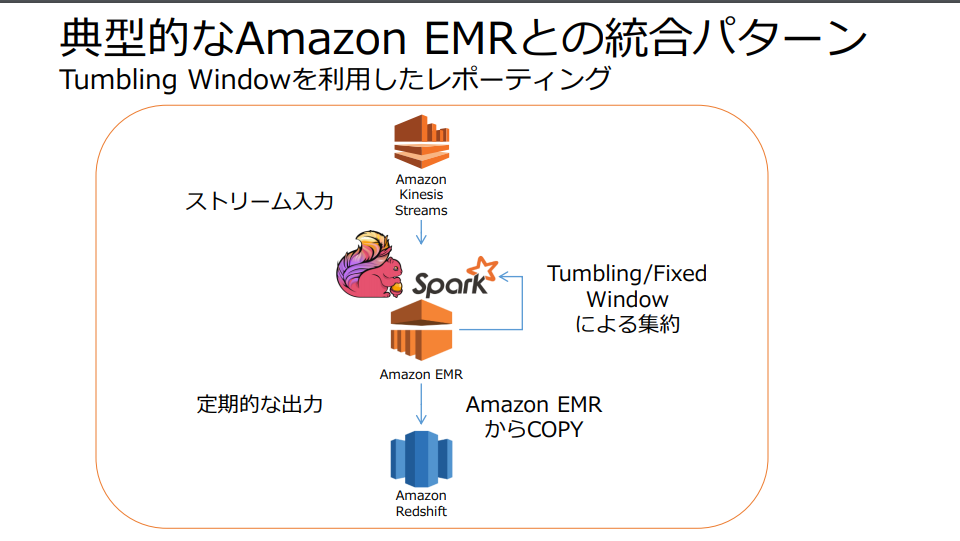
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
Kinesis StreamsとLambdaとの連携
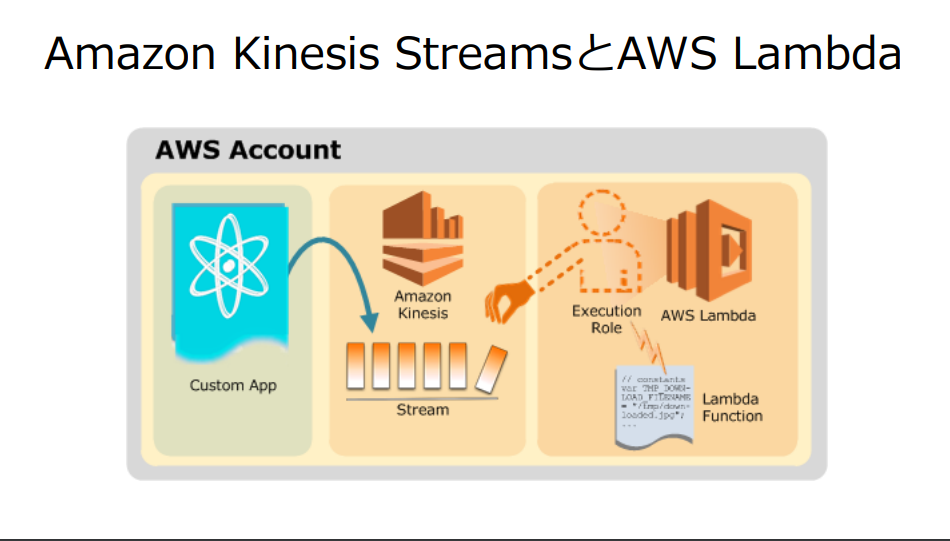
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
Kinesis Streamの処理データに対しLambdaを連携させることで、DynamoDBなどにデータを格納していくことが可能。
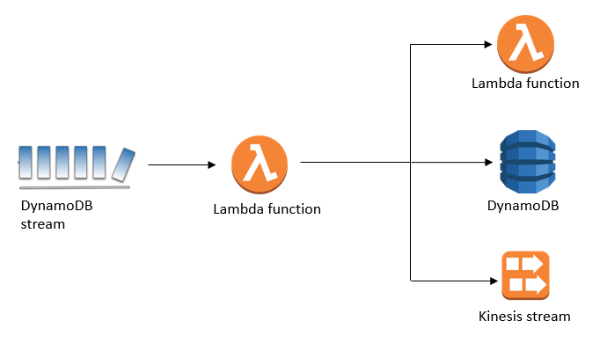
Amazon DynamoDB ストリームを使用して、順序付けされたデータをアプリケーション間でレプリケーションする方法 | Amazon Web Services ブログ より引用
Amazon Kinesis Firehose
ストリームデータをS3やRedshift、Elastic Searchなどへ簡単に配信する機能。基本的な特徴は以下の4点
- 管理不要:アプリケーション実装やインフラ管理が不要。
- データストアとダイレクトに統合:ストリームデータのバッチ化、圧縮、暗号化が可能。最短60秒でデータ配信可能
- シームレスにスケール
- サーバレスETL:Lambdaを利用してストリームデータを各配信先に形を変換することが可能
主要なコンセプト

https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
Amazon Kinesis Streamsとは違い、シャードが存在しない。そのため、パーティションキーの指定も不要となる。
特徴にあった通り制限なしにスケールしていく。
Amazon Kinesis Analytics
ストリームデータを標準的SQLクエリでリアルタイムに可視化・分析する機能。基本的な特徴は以下の3点
主要なコンセプト
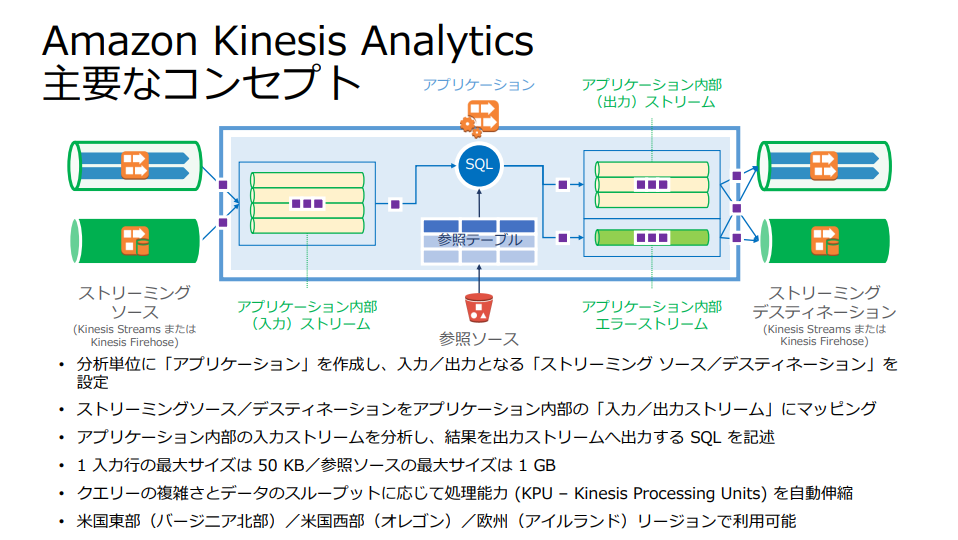
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
input側として、Kinesis StreamsかKinesis Firehoseを選択。
そのデータを使用してSQLで分析を行える。またS3に存在するマスター情報と結合することもできる。
またその結果を使用して、さらにKinesis StreamsかKinesis Firehoseを選択することで、その結果をS3やRedshift、RlasticSearchへ格納・描画したり、Kinesis Streamsでさらにストリーム処理をさせたりすることが可能。(以下図)

https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
Kinesis系機能3種類の組み合わせでストリーム処理を実施する
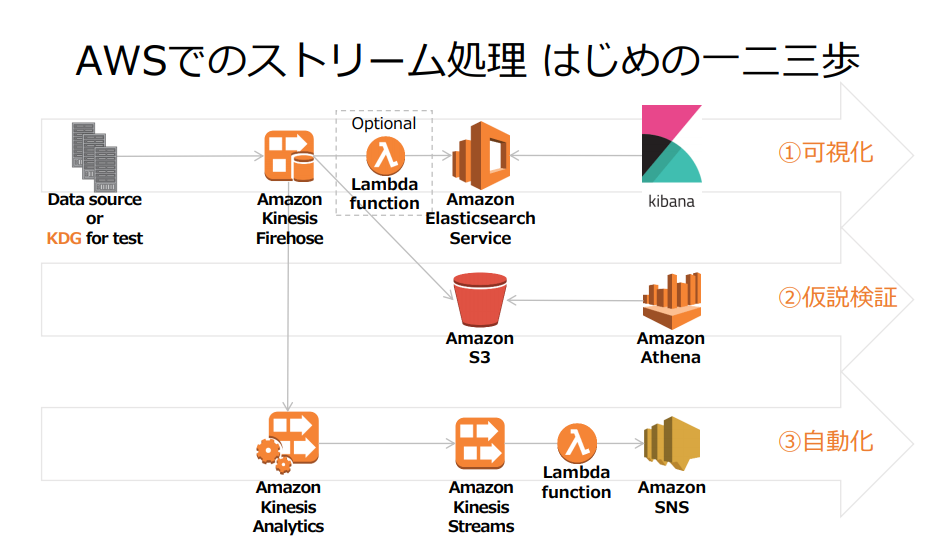
https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T3-5.pdf より引用
ストリームデータを可視化していくために、Kinesis FirehoseでLambdaを使用してETLし、その結果をElastic Searchが取り込む形。
アドホックに検証したい場合は、Kinesis FirehoseでLambdaを使用してETLし、その結果をS3に配置。S3のファイルをAthenaがロードしてクエリを実行し確認する形。
自動通知を行いたい場合は、Kinesis Firehose→Kinesis Analyticsを実行し、その結果をストリームデータとしてKinesis Streamsで実行、Lambdaを介してSNSで通知するという形。